Business Problem
- In the realm of social media, understanding the intricate dynamics of user interactions and community structures is important for businesses aiming to effectively engage with their target audience and capitalize on digital marketing opportunities.
- In this project, we aim to build a system capable of automatically analyzing social media networks and identifying and clustering communities that can significantly benefit businesses operating in this space. We can use the machine learning algorithm to perform
- Audience Segmentation
- Influencer Identification
- Customer Engagements
Approach
- We have graph dataset as input. We will solve this problem by performing below steps.
- Data Collection
- Graph Data Analysis
- Feature Engineering
- Exploratory Data Analysis
- Clustering
- Evaluation
- Conclusion
Data Collection and initial insights
- We have been provided a compressed dataset in gz format. Please refer link to code base
- We used gzip and shutil python library to convert it into facebook_combined.txt format for analysis.
- On further analysis, we came to know that we have unstructured node data with just two columns representing nodes in a graph. This is undirected graph.
- There are 88233 non null values in first and second column.
- First column has 3663 unique values and second has 4036 unique value
Graph Data representation for further analysis
- We used igraph library to do further analysis of undirected graph. Initial plotting of graph looked like below
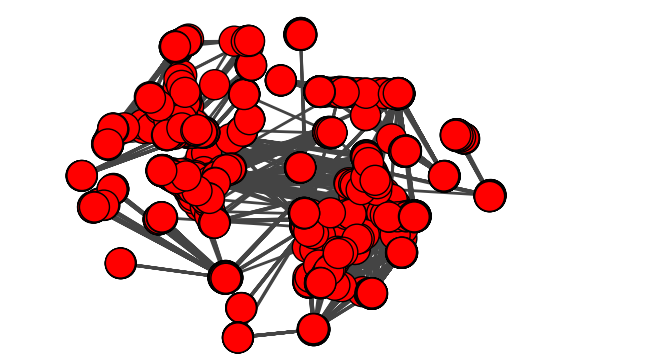
Feature Engineering
- We identified several features that we can use to identify clusters/groups.
- Node Degree. It is number of edges connected to the node. This information is very useful as in marketing if we want to propagate information quickly. High Node degree is desirable.
- Closeness Centrality: It determines how close a particular node is with all other nodes. Lower Closeness is desired.
- Betweenness Centrality: This metric defines and measures the importance of a node in a network based upon how many times it occurs in the shortest path between all pairs of nodes in a graph. High value is desired.
- Eigenvector Centrality: In general, vertices with high eigenvector centralities are those which are connected to many other vertices which are, in turn, connected to many others (and so on)
- Eccentricity:The eccentricity of a vertex is calculated by measuring the shortest distance from (or to) the vertex, to (or from) all vertices in the graph, and taking the maximum.
- Cluster Coefficient. The local clustering coefficient of a vertex (node) in a graph quantifies how close its neighbours are to being a clique (complete graph).
- Page Rank: PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is.
- Mean neighbor degree: This metrics can be calculated by using subgraphs with 2 hops for a given vertex.
Exploratory Data Analysis
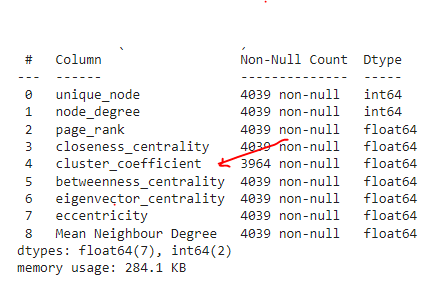
- On further analysis, we found that cluster coefficient has 75 null values.
- We decided to fill it with mean value
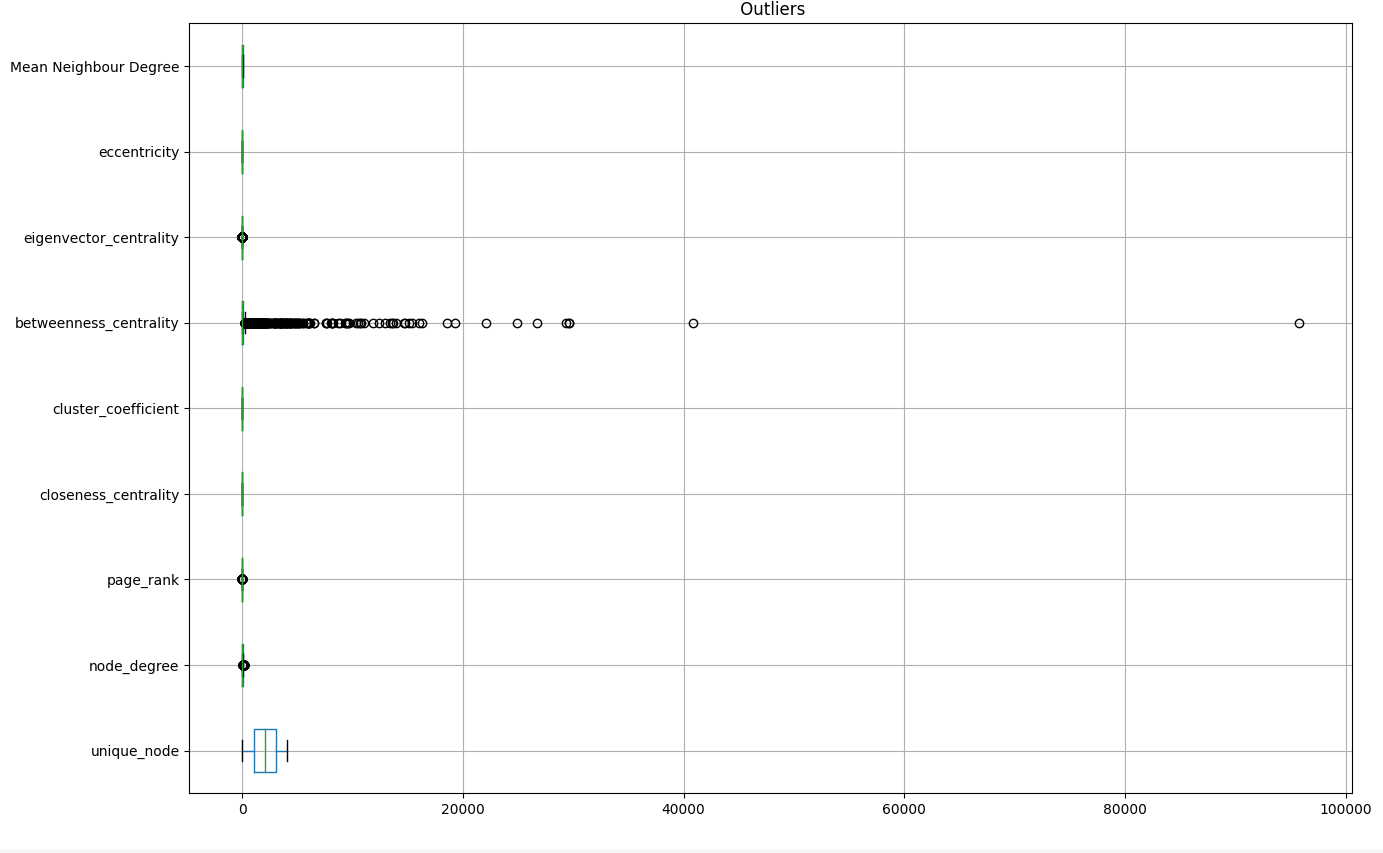
- Next we worked on identifying outliers based on Z score and removed outliers with Z score >2
- We are left with 3410 rows out of 4039
- We also analyzed box plot to identify further outliers and removed betweenness centrality.
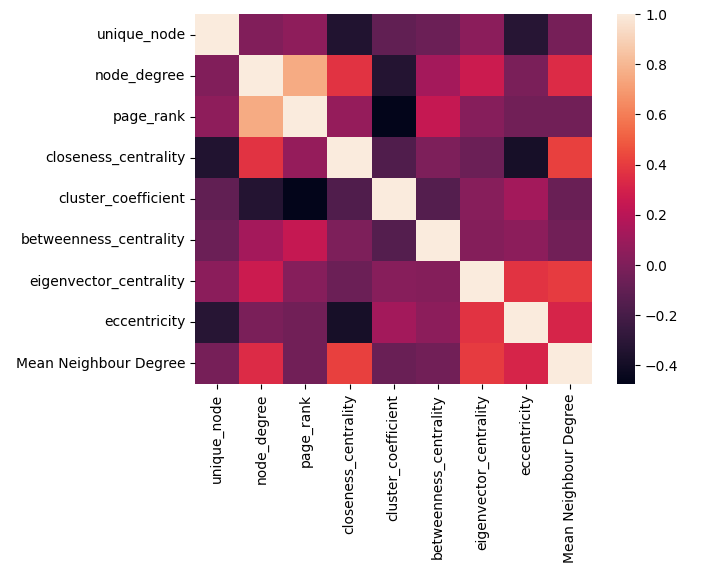
- On further analysis, we identified that node degree and page rank are highly correlated, hence dropped node degree.
Clustering
- We used K means clustering algorithm which is based on centroids to identify number of clusters.
- We started with number of initial clusters as 3 with 5000 iteration.
Evaluation
- Based on elbow curve analysis/SSD analysis and Silhoutte analysis, it appears that 6 is the optimum number of clusters for this problem
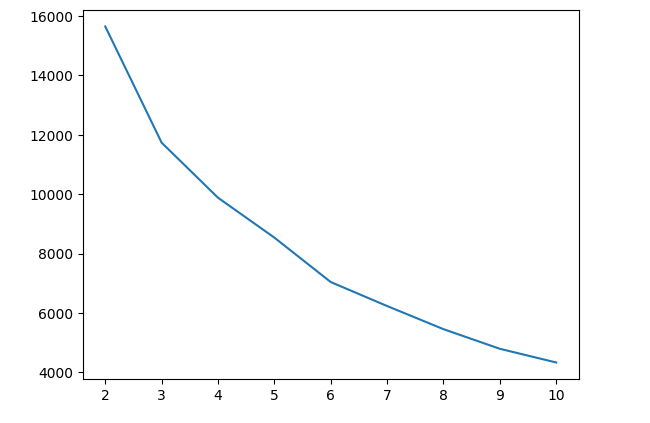
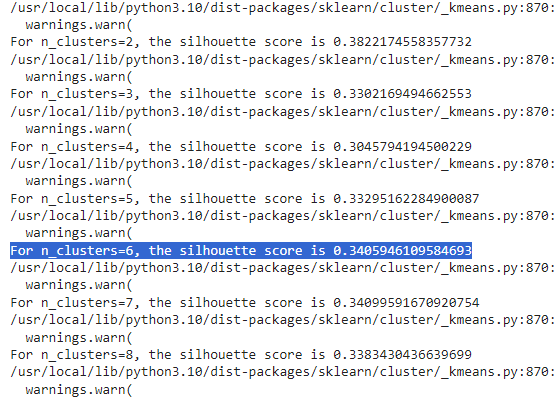
Conclusion
- It appears to be a weak cluster based on the data we have.
- After performing all EDA, Feature Engineering and ML clustering algorithm, it appears to have 6 clusters with ) 0.34 as score, which suggest that there is scope of model improvement.
Summary
Article Name
Machine Learning Mini Project - Social Networks
Description
In this project, we aim to build a system capable of automatically analyzing social media networks and identifying and clustering communities that can significantly benefit businesses operating in this space
Author
Naveen
0 Comments Leave a comment